


|
|
|
13.1.
Влияние сложности пространства гипотез на организацию работы системы
Такие системы,
как MYCIN, имеют дело с отдельной, очень специфической частью проблемной области
(в данном случае — медицины). В частности, система MYCIN диагностирует только
заболевания крови. Поскольку пространство состояний в системах, подобных MYCIN,
достаточно ограничено, в них можно использовать метод исчерпывающего поиска
в глубину.
А что делать,
если мы собираемся построить экспертную систему, имеющую дело со всеми возможными
заболеваниями, а не только с отдельным специфическим классом? Количество различных
заболеваний, известных врачам на сегодняшний день (диагностических категорий),
лежит, по разным оценкам, в диапазоне от двух до десяти тысяч. Нужно также учитывать,
что существуют пациенты, у которых обнаруживается до десятка заболеваний одновременно.
Как отметил Попл (Pople), в худшем случае программе, использующей обратную цепочку
рассуждений, придется при диагностировании таких пациентов проанализировать
около 1040 диагностических категорий!
Именно в тех
системах, в которых пространство решений потенциально может быть очень большим,
и проявляются преимущества метода иерархического построения и проверки гипотез.
Пространство поиска в таком случае может рассматриваться как дерево, представляющее
таксономию типов решений. Узлы более верхних уровней дерева соответствуют более
широким (а потому менее четко очерченным) категориям решений, чем узлы более
нижних уровней. Терминальные узлы дерева соответствуют совершенно конкретным
решениям. При такой организации пространства решений процесс уточнения гипотез
значительно упрощается, поскольку структура пространства решений может быть
использована для формирования эвристик управления последовательностью анализа.
На рис. 13.1
показана часть иерархической систематики заболеваний, которая используется в
системе CENTAUR. Корневым узлом этого фрагмента являются ЗАБОЛЕВАНИЯ_ ОРГАНОВ_ДЫХАНИЯ,
а все последующие узлы — различные виды таких заболеваний. Следующий уровень
узлов представляет наиболее общие категории заболеваний органов дыхания, а терминальные
узлы (листья) — конкретные заболевания, которые можно диагностировать и в дальнейшем
лечить.
Естественно,
если таким образом представить медицинские знания обо всех возможных болезнях,
то дерево очень сильно "разрастется". В системе INTERNIST организация
дерева привязана к основным органам — легким, печени, сердцу и т.п. Хотя иерархическая
организация и помогает выполнять поиск, она не устраняет проблему отыскания
наилучшего объяснения имеющегося набора данных (симптомов). Для этого необходимо
объединять гипотезы об отдельных болезнях и добиваться, чтобы в такой комбинированной
гипотезе были учтены все признаки и симптомы, обнаруженные у пациента.
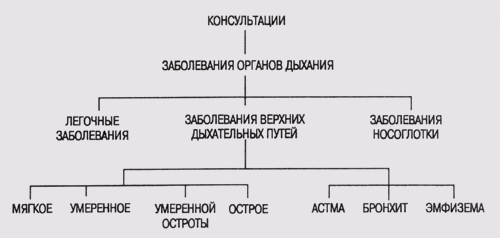
Рис. 13.1.
Иерархическое представление заболеваний органов дыхания
Методика вариативного
построения гипотез и их проверки оказывается особенно полезной в тех случаях,
когда
Один из этапов
подхода, использованного в CENTAUR, состоит в том, что просматривается, насколько
полно представление гипотетического заболевания совпадает с имеющимися данными
(симптомами, показаниями и т.п.). Узлы в дереве представления гипотез активизируются
имеющимися данными, конкретизируются, оцениваются и упорядочиваются по степени
"накрытия" имеющихся фактов. Узлы, "получившие" наиболее
высокие оценки, включаются в список заявок и в дальнейшем анализируются более
подробно. В первом приближении этот анализ сводится к выяснению, насколько имеющиеся
симптомы соответствуют каждому из дочерних узлов. Последовательно применяя такую
процедуру анализа, программа в конце концов формирует список терминальных
узлов с достаточно высокими оценками степени соответствия имеющимся данным.
13.1.
Обход дерева
В
самых общих чертах алгоритм выполнения иерархического построения и проверки
гипотез (НАТ-алгоритм) может быть представлен следующим образом. Предположим,
имеется дерево гипотез, которые могут быть активизированы на основе части имеющихся
данных. Активизированные гипотезы предполагают наличие и других данных, помимо
тех, что были использованы для их отбора, которыми мы можем располагать или
которые можно дополнительно затребовать.
НАТ-алгоритм
(1)
Считать исходные данные.
(2)
Для каждой исследуемой гипотезы сформировать оценку, которая показывает, какая
часть исходных данных учитывается этой гипотезой.
(3)
Определить ту гипотезу (узел) л, которая имеет наивысшую оценку.
(4)
Если п— терминальный узел, то завершить выполнение алгоритма. В противном случае
выделить в пространстве гипотез два подпространства К и L Подпространство К
должно содержать дочерние узлы п, а подпространство L — узлы-конкуренты п на
том же уровне дерева.
(5)
Собрать дополнительные данные, которые можно использовать для анализа гипотез
в подпространстве К, и провести оценку гипотез на основе этих дополнительных
данных. Пусть k— наивысшая оценка гипотез из К, а l— наивысшая оценка гипотез
из L
(6)
Если k выше, чем /, то положить п = k. В противном случае положить n = /.
(7) Перейти к п. 4.
|
|
|
 |
|||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||
|
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||