


|
|
|
23.4.2.
SCALIR — гибридная система для извлечения правовой информации
Узлы в сетевой
структуре системы SCALIR представляют прецеденты (дела, ранее рассмотренные
судами), статьи правовых актов и важные (ключевые) слова, которые встречаются
в подобных документах. Таким образом, структурно сеть разделена на три части
(слоя), как показано на рис. 23.3. В этой сети слой прецедентов и слой законодательных
актов разделены слоем узлов, представляющих ключевые слова (термины). Последние
связаны с документами, в которых они встречаются.
Таким образом,
в базовой структуре сети связь между узлами терминов и документов образует схему
индексации с взвешенными связями. В результате массив терминов отображается
как на массив прецедентов, так и на массив правовых актов.
Вместо того
чтобы связывать каждый термин с каждым документом, в котором он встречается,
в SCALIR вычисляется вес термина для каждого ключевого слова, связанного
с документом, как функция от частоты упоминания этого термина в данном документе
и частоты его упоминания во всем массиве документов. Интуитивно кажется, что
термином, наиболее подходящим для индексации некоторого документа, будет такой,
который часто появляется в этом документе, но редко во всех остальных. Полученное
значение сравнивается с пороговым, в результате чего каждый документ индексируется
примерно десятком ключевых слов. (Обращаю ваше внимание на тот факт, что на
схеме сети системы SCALIR показаны двунаправленные связи. Фактически каждая
из них представлена в системе парой однонаправленных связей, причем эти связи
могут иметь разные веса. Таким образом, не только термин позволяет найти документ,
но и по документу можно отыскать термин.)
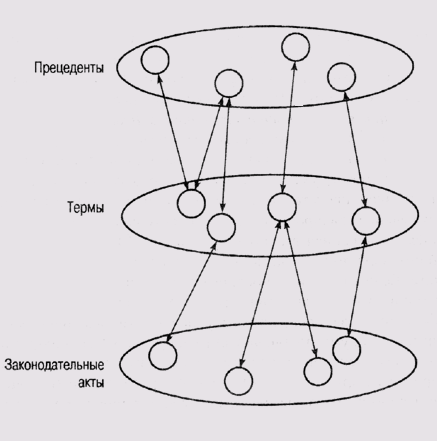
Рис. 23.3.
Сеть связности в системе SCAUR ([Rose, 1994])
При конструировании
сети в SCALIR сначала были организованы узлы для всех отобранных терминов, а
затем они связывались с узлами документов, причем связям назначались веса в
зависимости от значимости того или иного термина в контексте данного документа.
Такой тип
связей (в документации они названы С-связями) не является единственным в SCALIR.
Существуют и символические связи (S-связи), которые во многом напоминают связи
в семантических сетях, поскольку маркированы и имеют постоянные веса. С помощью
связей этого типа в сети представлены отношения между документами, например
один документ цитирует другой, в одном судебном решении критикуется другое,
один правовой акт ссылается на другой и т.д. Таким образом, S-связи представляют
знания в явном виде.
В целом сеть
сиетемы SCALIR содержит порядка 13 000 узлов терминов, около 4 000 узлов прецедентов
и около 100 узлов законодательных актов. Между узлами терминов и прецедентов
организовано приблизительно 75 000 связей, а между узлами терминов и законодательных
актов — около 2 000 связей. Кроме того, существует около 10 000 символических
связей между узлами прецедентов. Роуз не счел нужным останавливаться на том,
каких усилий потребовало создание подобной сети, но можно предположить, что
такие ключевые задачи, как извлечение терминов и цитирование, были решены программно,
а затем на основании этой информации автоматически сформированы узлы сети и
связи между ними. Нужно принять во внимание и тот факт, что большинство горидических
документов было уже ранее обработано публикаторами, которые составили достаточно
полные индексы цитирования и ключевых слов.
Описанная
сеть была затем использована в качестве базовой информационной структуры для
извлечения документов. В основу функционирования системы положен принцип распространяющейся
активности (spreading activation). Этот принцип не нов — ранее он использовался
Квиллианом для работы с семантическими сетями (см. об этом в главе 6). Использование
этого формального аппарата позволяет выяснить, существует ли какое-либо отношение
между узлами в сети. Для этого запускается процесс распространения маркеров
от узлов, представляющих интерес, и анализируется, произошло ли где-либо в сети
"пересечение" распространяющихся маркеров.
Основная идея,
положенная в основу работы SCALIR, состоит в том, что уровень активности данного
узла должен быть пропорционален его "уместности" в рассматриваемом
контексте. Если в результате обработки запроса возбуждается некоторое число
узлов слоя терминов, это должно привести к возбуждению узлов тех документов,
которые касаются данного запроса, причем уровень возбуждения зависит от того,
насколько тот или иной документ отвечает сути запроса. Узлы, воспринимающие
запросы, являются, по сути, сенсорными узлами нейронной сети, от которых возбуждение
по С-связям передается другим узлам. В процессе распространения возбуждения
в дело включаются и S-связи, которые передают возбуждения от одних узлов документов
другим, связанным с ними. Таким образом, символические связи отражают знания
о том, что если определенный документ имеет отношение к полученному запросу,
то, скорее всего, и связанный с ним другой документ также имеет отношение к
этому запросу. Веса символических связей фиксированы, поскольку сила такой ассоциативной
зависимости может быть оценена заранее.
Существуют
два свойства функции активизации сети, которые представляются крайне желательными
с точки зрения приложений, требующих ассоциативного поиска информации. Эти свойства
влияют на выбор способа возбуждения сенсорных узлов, воспринимающих запросы
пользователей, методики назначения весов связям и формы функции активизации.
(1) Количество
активности, которое вносится в систему, не должно зависеть от размерности запроса.
(2) В каждом
очередном цикле распространения активность не должна возрастать.
Если первое
из указанных требований не будет выполняться, то запрос, состоящий из одного
слова, приведет к меньшей активности сети, чем многословный. При этом окажется,
что в ответ на более ограниченный многословный запрос система извлечет больше
документов, чем в ответ на более свободный однословный, а это противоречит нашим
интуитивным ожиданиям. Если же сеть не обладает вторым из сформулированных свойств,
то будет извлечено слишком много документов, имеющих крайне слабое касательство
к сути запроса, т.е. система будет производить много "информационного мусора".
Для того чтобы
система обладала первым свойством, нужно на стадии предварительной обработки
запроса распределить между входными узлами фиксированное количество активности.
Вторым свойством система будет обладать в том случае, если сумма весов выходных
связей не будет превышать единицы и, следовательно, значение функции активизации
будет меньше или равно ее аргументу.
С-связи используют
линейную функцию активизации, которая содержит константу сдерживания (retention
constant) р, как показано в приведенном ниже выражении. Значение этой константы
определяет, какая часть активности узла сохраняется в последующем цикле возбуждения,
а какая распространяется дальше по сети.
ai(t
+ 1) = р аj(t)
+ (1 - p) Sumj [Wij aj(t)]
Совершенно
очевидно, что приведенная функция активизации будет удовлетворять сформулированным
требованиям, поскольку ai(t +1)=< ai(t) до тех
пока, пока Sumj[Wij= < 1]
Функция такого
же вида использована и в работе [Belew, 1986]. Роуз следует идеям, изложенным
в этой работе, и в отношении организации управления активностью сети в SCALIR.
Эти параметры
используются в алгоритме распространения активности по сети SCALIR, который
в упрощенном виде представлен ниже. Этот алгоритм реализует метод поиска в ширину,
начиная со входных узлов восприятия запроса (QUERY-NODES) и заканчивая всеми
взвешеннымисвязями.
Установить
исходное значение OS.
Включить в
множество ACTIVE-NODES узлы из множества QUERY-NODES.
Цикл {
Если имеется
запрос, установить уровни активности узлов в QUERY-NODES.
Включить в
множество RESPONSE-SET все узлы из ACTIVE-NODES, чья активность превышает OS.
Удалить из
множества ACTIVE-NODES все узлы, чья активность ниже Oq.
Добавить в
множество ACTIVE-NODES все узлы, связанные с узлами, уже включенными в ACTIVE-NODES.
Обновить значение
активности всех узлов множества ACTIVE-NODES, используя функцию активизации.
Рассортировать
узлы в множестве ACTIVE-NODES по уровню активности. Уменьшить значение Os.
}
пока не будет
выполнено (OS =< Oq) или (ACTIVE-NODES = 0).
В упрощенном
варианте не рассматривается использование параметра, ограничивающего ширину
пространства поиска. Кроме того, мы опустили в этой формулировке алгоритма и
анализ максимального размера множества выходных узлов. Ограничение множества
выходных узлов прекращает выполнение поиска после того, как выделено предельное
количество извлекаемых документов.
Значение большинства параметров, используемых в процессе управления активностью сети, устанавливается эмпирически. Настройка же весов связей между узлами сети Wij представляет собой, по сути, процесс обучения системы, который мы вкратце рассмотрим в следующем разделе.
|
|
|
 |
|||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||
|
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||