


|
|
|
23.3.
Использование прецедентов для обработки исключений
В этом разделе
мы рассмотрим способ совместного использования правил и прецедентов, отличный
от того, какой применен в системе ODYSSEUS. Роль прецедентов при новом подходе
состоит не в том, чтобы содействовать модификации правил, а в том, чтобы при
обработке исключений служить дополнением тем знаниям, которые представлены в
правилах. Таким образом, каждый из компонентов занимается тем, что у него лучше
получается, — правила имеют дело с обобщениями предметной области, а прецеденты
— с отдельными нетипичными случаями.
Как уже было
не раз продемонстрировано в предыдущих главах (см., например, главы 10-15),
построение набора правил для экспертной системы— задача далеко не тривиальная.
Помимо сложностей, сопряженных с извлечением и представлением знаний, существует
еще и проблема полноты охвата предметной области набором правил. В идеале база
правил должна быть корректной, непротиворечивой (по крайней мере, в рамках принятой
стратегии разрешения конфликтов) и полной. Но по мере того, как количество правил
расширяется, а сами правила усложняются, достичь такого идеального состояния
становится все труднее.
Особенно сложно
учесть в правилах все возможные исключения. Такая попытка приводит к чрезвычайному
усложнению правил. Утверждение, что не бывает правил без исключений, давно уже
стало общим местом. Иногда эту проблему пытаются решить включением в набор множества
"мелких" правил, которые должны активизироваться в таких исключительных
ситуациях. Но это означает возлагать на правила несвойственную им функцию —
обрабатывать не общий случай, а частный.
Голдинг и
Розенблум предложили использовать в экспертных системах гибридную архитектуру,
в которой при решении проблем методика использования порождающих правил сочетается
с методикой использования прецедентов [Gaiding and Rosenbloom, 1996]. Идея
состояла в том, что механизм обработки прецедентов должен использоваться для
критического анализа результатов применения правил. Это выполняется путем поиска
прецедентов, аналогичных рассматриваемому случаю, если последний можно считать
исключением из правила. Такой подход требует, чтобы база прецедентов была индексирована
по применяемым правилам. Авторы предложили и соответствующую меру близости,
которая позволяет оценить степень подобия текущего случая и прецедента (рис.
23.1).
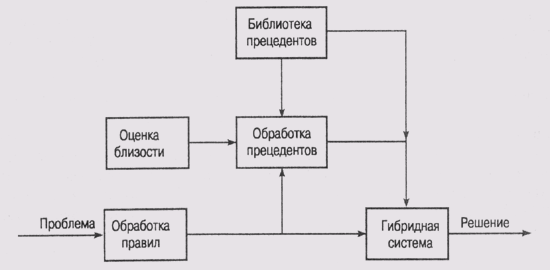
Рис. 23.1.
Архитектура гибридной системы, использующей правила и прецеденты
Основная идея
системы очень проста и элегантна. Сначала для решения текущей проблемы применяются
правила, в результате чего формируется некоторое решение. Затем просматривается
библиотека прецедентов на предмет выявления в ней ранее ветречавшегося случая
исключения из использованных правил. Алгоритм работы системы приведен ниже.
Цикл, ПОКА
не будет получено решение
{
1 . Для выбора
следующей операции использовать правила.
2. Поиск в
библиотеке "неотразимых" прецедентов, которые предлагают противоположный
вариант выбора операции.
3. Если прецедент
найден, использовать предлагаемый в нем вариант операции. Иначе использовать
тот вариант, который предлагается правилами.
}
Обратите внимание
на то, что обращение к правилам и прецедентам выполняется в каждом цикле. (Если
программа не сможет найти ни правила, которое можно было бы применить, ни прецедента,
она останавливается.)
Для того чтобы
предложенная идея стала работоспособной, прецеденты в библиотеке должны быть
проиндексированы по правилам, которым они противоречат. Рассмотрим, например,
правило страховки водителей транспортных средств:
"Мужчины
не старше 25 лет платят страховой взнос по повышенному тарифу".
Такое правило
должно быть связано в библиотеке с прецедентом, в котором упоминается 18-летний
юноша, успешно прошедший тесты повышенной сложности и выплачивающий взнос по
сниженному тарифу.
На основании
каких соображений принимается решение, является ли прецедент "неотразимым"
или нет? Предложенное Голдингом решение состоит в следующем. Когда мы проводим
аналогию между прецедентом и текущим случаем, мы тем самым формируем некое неявное
правило, скрытое от посторонних глаз. Предположим, что в нашем примере речь
идет о водителе-мужчине 20 лет, который имеет квалификацию повышенной категории,
и мы обнаружили аналогичный прецедент, но в нем речь шла о 1 8-летнем водителе.
Эта аналогия сформирует неявное правило в виде
"Мужчины
не старше 25 лет, имеющие повышенную квалификационную категорию, платят страховой
взнос по сниженному тарифу".
Предположим,
что при оценке степени близости, которая необходима для извлечения и последующего
анализа прецедентов, возраст водителей разделяется на диапазоны, скажем "до
25 лет", "от 25 до 65 лет" и "свыше 65 лет". Эта мера
близости оценит рассматриваемый нами случай и прецедент как очень похожие, поскольку
совпадают возрастная категория и пол.
Можно протестировать
это правило и на остальных прецедентах в библиотеке и оценить, какой процент
выявленных прецедентов оно накрывает. Любой прецедент с мужчиной-водителем повышенной
квалификационной категории, чей возраст не превышает 25 лет и который выплачивает
взнос по повышенному тарифу, будет считаться исключением и, следовательно, снижать
рейтинг прецедента. Если же случаи достаточно похожи, а правило достаточно точное,
то аналогия считается "неотразимой" и компонент обработки прецедентов
"выигрывает". В противном случае выигрыш будет за применяемым правилом,
и в окончательном решении будет использован вариант, следующий из правила.
Таким образом,
"неотразимость" зависит от трех факторов:
4 достоверности
оценки точности, которая определяется размером выборки, на которой эта оценка
сформирована.
Авторы продемонстрировали возможности предложенной архитектуры на примере задачи определения произношения имен. Реализованная ими система, получившая название ANAPRON, содержит около 650 лингвистических правил и 5000 прецедентов. Результаты испытания системы показали, что она обладает более высокой производительностью, чем системы-аналоги, использующие либо только правила, либо только прецеденты.
|
|
|
 |
|||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||
|
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||