


|
|
|
14.2.2.
Использование текущего контекста для управления структурой задачи
Помимо информации
о компонентах и ограничениях, в рабочей памяти системы R1 содержатся также символические
структуры, определяющие текущий контекст вычислительного процесса. Это помогает
разделить задачу конфигурирования на подзадачи. В первом приближении можно считать,
что каждой такой подзадаче соответствует активизация определенной группы правил.
Более того, эти подзадачи можно организовать, в иерархическую структуру с временными
отношениями между ними и таким образом наложить на задачу конфигурирования структуру,
в чем-то схожую с планом.
Другими словами,
главная задача, скажем "разработать конфигурацию модулей VAX-11/780 соответственно
данному заказу", может быть разбита на ряд подзадач, например "проверить
корректность заказа", "подобрать компоненты в соответствии с заказом
(возможно, ранее скорректированным)". Выполнение этих двух задач приведет
к выполнению главной задачи. Естественно, что порядок выполнения подзадач не
может быть произвольным, — вряд ли кому-то придет в голову сначала подобрать
компоненты в соответствии с заказом, а потом проверять, не допущена ли в заказе
ошибка.
Программа
R1 разбивает задачу конфигурирования на шесть подзадач, каждая из которых, в
свою очередь, может быть разбита на более мелкие подзадачи.
(1) Проверить
заказ, уточнить все пропущенные в нем сведения и исправить замеченные ошибки.
(2) Включить
в конфигурацию модуль центрального процессора, все компоненты, непосредственно
связанные с центральным процессором, и определить состав блоков основной стойки
комплекса.
(3) Включить
в конфигурацию модули расширения шины UNIBUS, определить состав блоков в стойке
расширения интерфейса.
(4) Включить
в конфигурацию генпанели, распределить их между стойками и связать с блоками
расширения интерфейса и обслуживаемыми устройствами.
(5) Составить
план расположения стоек, распределить блоки периферийных устройств между стойками
с учетом длин связей.
(6) Разработать
схему соединения стоек и выбрать типы кабелей.
По отношению
к порядку выполнения подзадач эта иерархическая схема может быть либо детерминированной,
либо недетерминированной. Если в пределах подзадачи на любую заданную
глубину порядок выполнения операций фиксирован, то говорят, что используется
детерминированный анализ задач. В противном случае — допустимы отклонения в
последовательности выполнения подзадач на любом уровне — считается, что используется
недетерминированный анализ задач.
В системе
R1 детерминированный анализ используется только в отношении части задач, которые
всегда выполняются в одном и том же порядке. Достигается такое упрощение следующим
образом. Множество правил в R1 служит просто для управления символами контекста
— теми элементами рабочей памяти системы, которые несут информацию о текущем
положении системы в иерархии задач. Одни правила этой группы определяют условия,
при которых нужно инициировать новую подзадачу, — при этом в рабочую память
добавляются новые символы контекста, а другие правила распознают, закончилось
ли выполнение подзадачи, и удаляют символы контекста из рабочей памяти. Все
остальные правила содержат элементы условий, анализирующие символы контекста,
а потому они выполняются только в том случае, если "активен" соответствующий
контекст. Чтобы разобраться в том, как работает этот механизм на практике, нужно
остановиться хотя бы вкратце на стратегии разрешения конфликтов, используемой
в R1.
Каждый символ
контекста содержит имя контекста, например "подсоединение_источника_питания",
символ, который несет информацию о том, активен данный контекст или нет, тэг
времени, который несет информацию о том, как давно контекст был активизирован.
Правила, которые распознают, когда должна быть запущена на выполнение новая
подзадача, используют с этой целью текущее состояние частичной конфигурации.
Те правила, в условной части которых имеется соответствующий символ контекста,
получают более высокий приоритет в цикле "распознавание состояния — действие".
Общепринято
размещать условия распознавания контекста в самом начале антецедентной части
порождающего правила. В результате, если это условие не соблюдается, не тратится
время на анализ остальных. Кроме того, стратегия разрешения конфликтов в системе
R1 (она получила название ME А) обращает особое внимание на первое условие в
правиле после его конкретизации перед возможным применением. У правил, которые
деактивизируют контекст, антецедентная часть состоит из единственного символа
контекста. Такое правило будет применено только после всех остальных правил,
чувствительных к тому же контексту. Это пример использования стратегии специфики.
Следуя этой стратегии, система R1 сначала выполняет все действия, связанные
с определенным контекстом, а уже после этого изменяет его.
Основная эвристика
специфики состоит в следующем. Если существуют два конфликтующих правила Rule
1 и Rule 2 и условия, специфицированные в правиле Rule 2, являются подмножеством
условий, специфицированных в правиле Rule 1, то правилу Rule 1 дается более
высокий приоритет, чем правилу Rule 2. Можно и по-другому рассматривать эту
эвристику. Правило Rule 2 является более "общим", чем правило Rule
1, и оно обрабатывает по умолчанию те случаи, которые не "охватываются"
более специализированным правилом Rule 1. При этом фактически правило Rule 1
имеет дело с исключениями из общего правила Rule 2, поскольку в нем принимаются
во внимание дополнительные условия (рис. 14.1).
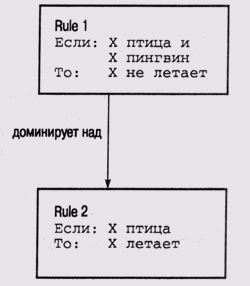
Рис. 14.1.
Пример применения стратегии специфики: правило Rule 1 доминирует над правилом
Rule 2
В языке
OPS5 (а также в CLIPS) эвристика специфим Машина логического вывода частично
упорядочивает кон в качестве критерия упорядочения количество проверок правилах.
В частности, выполняется анализ соответствия констант или переменных заданным
значениям. Доминировать будут те правила, для которых потребуется наибольшее
количество проверок. В любом случае применение стратегии МЕА помогает упорядочить
применение правил, сделать его более или менее регулярным.
Мак-Дермот
(McDermott) конкретизировал использование контекстов состояния применительно
к задаче формирования конфигурации вычислительной системы. Он считает, что этот
способ довольно хорошо передает подход к решению аналогичных задач экспертом-человеком.
Нужно, однако, отметить, что система R1 не располагает реальными знаниями о
свойствах контекста, с которым имеет дело. Имена контекста— это только некоторые
символические обозначения, в отличие от компонентов, с которыми связаны все
виды атрибутов и значений. Следовательно, система R1 не может "рассуждать"
о контекстах так же, как она "рассуждает" о компонентах или ограничениях.
Система просто распознает состояние, когда ей необходим новый контекст или когда
завершены все операции, связанные с данным контекстом.
14.1.
Стратегии разрешения конфликтов LEX и МЕА
В
главе 5 были упомянуты стратегии разрешения конфликтов LEX и МЕА, реализованные
в языке CLIPS. Ниже будет в общих чертах рассмотрена реализация стратегии МЕА,
которая использована в системе R1/XCON.
Как
было показано в главе 3, анализ "средство — анализ результата" является
абстрактным режимом формирования цепочки обратного логического вывода в случае,
когда определена некоторая цель. Этот режим позволяет выбрать операторы или
правила, которые способны сократить "расстояние" между текущим и заданным
целевым состоянием проблемы. Несложно показать, как этот режим можно использовать
в контексте порождающей системы с обратной стратегией логического вывода, например
MYCIN, когда весь процесс начинается с цели самого верхнего уровня общности
(см. главу 3). В системах, использующих прямой логический вывод, которые строятся
на основе языковых средств OPS5 или CLIPS, применяется стратегия разрешения
конфликтов МЕА. Основанный на ней режим управления позволяет программе "продвигаться"
по неявно заданному дереву целей, которые представлены специальными лексемами
в рабочей памяти экспертной системы.
Алгоритм
МЕА включает пять шагов. Напомним, что конфликтующее множество правил включает
те конкретизированные правила, которые должны быть активизированы в течение
одного и того же цикла вычислений. Конкретизация правила представляет собой
совокупность обобщенной формулировки правила и значений используемых в нем переменных
.
(1)
Исключить из конфликтующего множества те правила, которые уже были применены
в предыдущем цикле. Если после этого множество стало пустым, прекратить процесс.
(2)
Сравнить "новизну" элементов в рабочей памяти, которые соответствуют
первым элементам условий в конкретизированных правилах, оставшихся в конфликтующем
множестве. Приоритет отдается тем правилам, которые обращаются к самым "свежим"
элементам рабочей памяти,— эти правила "доминируют" над остальными.
Если существует единственное такое правило, то оно выбирается для применения,
после чего процесс должен быть прекращен. В противном случае, если имеется несколько
доминирующих правил с
равным
приоритетом, они сохраняются в конфликтующем множестве, а прочие из него удаляются.
Далее выполняется переход к шагу (3).
(3)
Упорядочить конкретизированные правила по "новизне" остальных элементов
условий в правилах. Если доминирует единственное правило, оно применяется и
затем процесс прекращается. Если же доминируют два или несколько правил, то
они остаются в конфликтующем множестве, а остальные удаляются из него. Затем
выполняется переход к шагу (4),
(4)
Если по критерию "новизны" элементов условий отобрано несколько правил
с равными показателями, то сравнивается другой показатель правил — показатель
специфики. Предпочтение отдается тому правилу, применение которого требует проверки
наибольшего количества условий в рабочей памяти. Если "претендентов"
окажется несколько, остальные удаляются из конфликтующего множества и выполняется
переход к шагу (5).
(5)
Применяется правило, выбранное произвольным образом из оставшихся в конфликтующем
множестве, и процесс прекращается.
Таким образом, стратегия МЕА объединяет в едином алгоритме анализ таких показателей, как повторяемость, новизна и специфика. Алгоритм LEX практически идентичен алгоритму МЕА за одним исключением — в нем отсутствует шаг 2), а на шаге 3) сравниваются все элементы условий конкретизированных правил и связанных с ними элементов рабочей памяти. Первые элементы условий, которые использовались на шаге 2), являются, как правило, лексемами задач в рабочей памяти (в главе 5 приведен пример программы, которая манипулирует такими лексемами).
|
|
|
 |
|||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||
|
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||